Autotimes 모델 학습
지난번 소개한 AutoTimes 모델을 실제 데이터로 학습시켜 트레이딩 성과를 살펴보겠습니다.
AutoTimes

지난번 AutoTimes 논문에 대해 이야기를 했습니다.
핵심은 시계열 문제에서 전통적인 딥러닝 모형이나 통계 모델이 갖는 한계를 넘어
LLM을 시계열 예측에 활용하려는 연구가 많은데
기존의 LLM4TS 연구의 문제점을 지적하고 (non-autoregressive)
LLM이 갖춘 next-token prediction, 즉 autoregressive 특성을 살려 연구를 진행했습니다.
LLM4TS vs AutoTimes
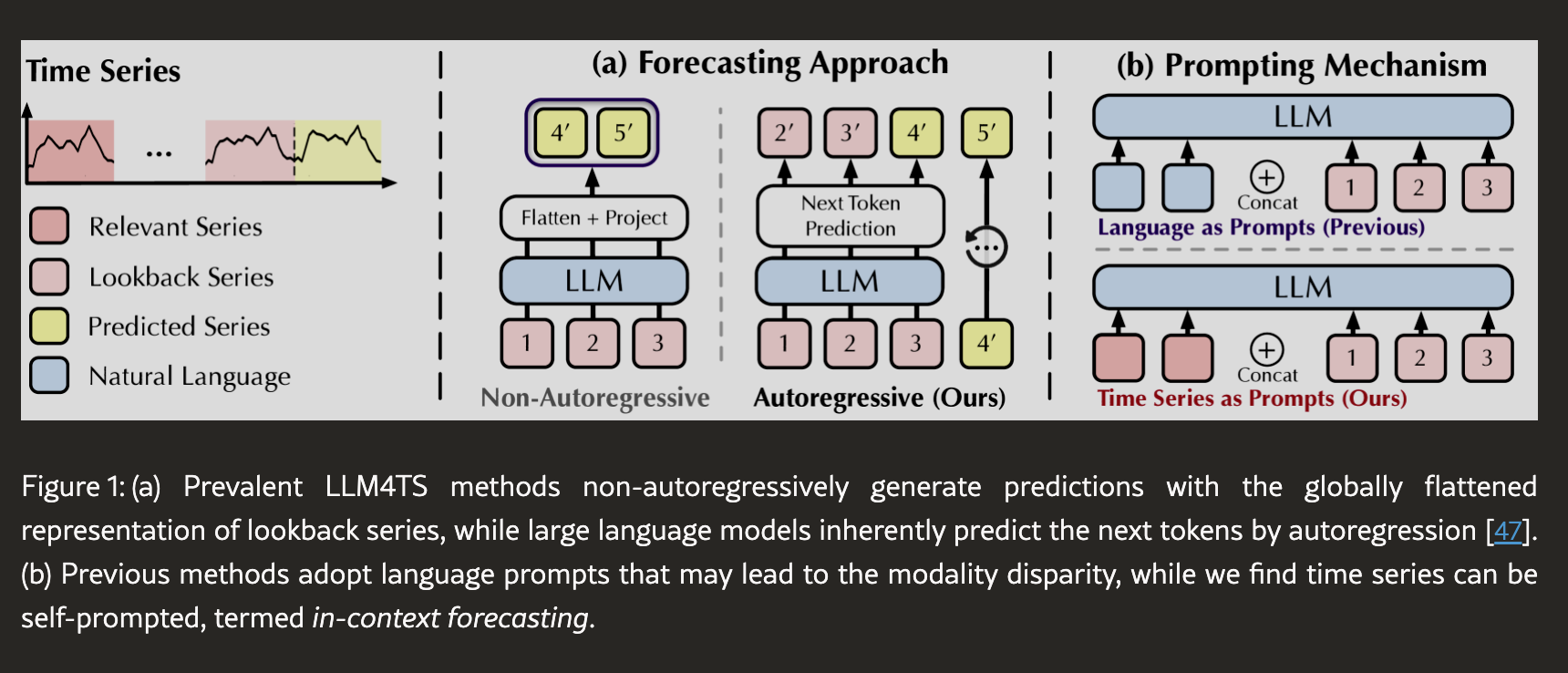
지난번에 이야기를 했기 때문에 깊은 이야기를 오늘 또 다루지 않겠지만
기존 LLM을 활용한 시계열 예측과 AutoTimes의 차이점인 Auto-regressive를 이용하냐
그러지 않느냐 차이를 보여주는 그림입니다.
시계열 데이터를 하나의 flatten 벡터로 변환하여 한 번에 미래를 내뱉게 했습니다.
AutoTimes는 시계열을 토큰처럼 segment로 나누고
LLM이 하는 것처럼, 다음 토큰을 생성하는 방식으로 예측을 진행합니다.
사실 이 논문이 arxiv에 나와있지만
제가 예전에 이야기 했던 TradingGPT 연구와 많은 유사점이 보입니다.
AutoTiems 구현
해당 연구를 진행한 칭화대학교에서 공식적인 AutoTimes 코드를 공개하긴 했지만
특정 LLM 버전에 국한적인 코드로 제공해서 제가 일부 백본과 파이프라인을 분리해서
좀 더 효율적으로 구현체를 만들어봤습니다.
학습 시 hugging-face에서 LLM을 가져와서 디코더 백본을 제어할 수 있도록 구현했고
@dataclass
class BackboneInitArgs:
model_name: str
revision: Optional[str] = None
cache_dir: Optional[str] = None
device: str = "cpu"
dtype: str = "float32"
gradient_checkpointing: bool = False
use_flash_attention: bool = False
freeze: bool = True
class DecoderBackbone:
"""
Thin wrapper around a Hugging Face decoder-only LLM.
- inputs_embeds 경로 지원
- timestamp 임베딩 생성
- dtype/device/마스크/flash-attn/GC 안전장치
"""토큰화 방식에서는 코드에서는 unfold로 길이 token_len씩 잘라
선형·MLP 인코더/디코더에 통과시키지만,
저는 AutoTimes는 SegmentEmbedder/SegmentProjector 클래스로
세그먼트 길이·피처 수를 명시적으로 처리하고
GELU가 포함된 2단 MLP를 사용합니다.
덕분에 단변량·다변량 모두 동일 인터페이스로 지원됩니다.
class SegmentEmbedder(nn.Module):
"""
Encodes raw time-series segments into the LLM latent space.
Supports both univariate (S,) and multivariate (S, C) segments.
"""
def __init__(
self,
segment_length: int,
hidden_dim: int,
embed_dim: int,
num_features: int = 1,
):
super().__init__()
self.segment_length = segment_length
self.num_features = num_features
# 입력 차원: 단변량은 segment_length, 다변량은 segment_length * num_features
input_dim = segment_length * num_features
self.network = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, embed_dim),
)
class SegmentProjector(nn.Module):
"""
Projects LLM hidden states back into the time-series segment space.
Supports both univariate and multivariate output.
"""
def __init__(
self,
embed_dim: int,
hidden_dim: int,
segment_length: int,
num_features: int = 1,
):
super().__init__()
self.segment_length = segment_length
self.num_features = num_features
# 출력 차원: 단변량은 segment_length, 다변량은 segment_length * num_features
output_dim = segment_length * num_features
self.network = nn.Sequential(
nn.Linear(embed_dim, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, output_dim),
)
class AutoTimesForecaster(nn.Module):
"""
PyTorch implementation of AutoTimes.
"""
def __init__(
self,
config: AutoTimesConfig,
backbone: Optional[DecoderBackbone] = None,
):
def _prepare_batch(
self,
segments: torch.Tensor,
timestamp_embeddings: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
if segments.ndim == 2:
segments = segments.unsqueeze(0)
if timestamp_embeddings.ndim == 2:
timestamp_embeddings = timestamp_embeddings.unsqueeze(0)
segments = segments.to(self.device)
timestamp_embeddings = timestamp_embeddings.to(self.device)
norm_segments = self.revin(segments, mode="norm")
segment_tokens = self.segment_embedder(norm_segments) + timestamp_embeddings
return norm_segments, segment_tokens
def forward(
self,
segments: torch.Tensor,
timestamp_embeddings: torch.Tensor,
target_segments: Optional[torch.Tensor] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Teacher-forced forward pass used during training.
Returns the predicted future segments aligned with the input.
Both predictions and targets are denormalized (original scale).
Args:
segments: 입력 세그먼트 (B, N, S) 또는 (B, N, S, C)
timestamp_embeddings: 타임스탬프 임베딩 (B, N, D)
target_segments: 타겟 세그먼트 (B, M, S) 또는 (B, M, S, C), None이면 segments에서 추출
Returns:
predicted_segments: 예측된 세그먼트 (역정규화된, 원본 스케일)
targets: 타겟 세그먼트 (역정규화된, 원본 스케일)
"""
norm_segments, token_embeddings = self._prepare_batch(
segments, timestamp_embeddings
)
# Teacher forcing: feed everything except the final token.
inputs = token_embeddings[:, :-1, :]
hidden_states = self.backbone.forward_hidden_states(inputs)
predicted_segments_all = self.segment_projector(hidden_states)
# 타겟 처리
if target_segments is not None:
target_segments = target_segments.to(self.device)
# 타겟은 segments의 통계를 재사용 (같은 배치의 일부이므로)
# norm_segments에서 해당 부분 추출
forecast_len = target_segments.shape[1]
# segments는 (B, N, S) 또는 (B, N, S, C), target_segments는 (B, forecast_len, S) 또는 (B, forecast_len, S, C)
# segments의 마지막 forecast_len 세그먼트를 target으로 사용
history = norm_segments.shape[1] - forecast_len
targets_norm = norm_segments[:, history:, ...]
# predicted_segments를 targets의 길이에 맞춤 (마지막 forecast_segments 개만)
predicted_segments_norm = predicted_segments_all[:, -forecast_len:]
else:
# Align predictions with ground truth: skip history token.
targets_norm = norm_segments[:, 1:, ...]
# predicted_segments도 같은 길이로 맞춤
predicted_segments_norm = predicted_segments_all
# 역정규화: 예측값과 타겟 모두 역정규화해서 반환
predicted_segments = self.revin(predicted_segments_norm, mode="denorm")
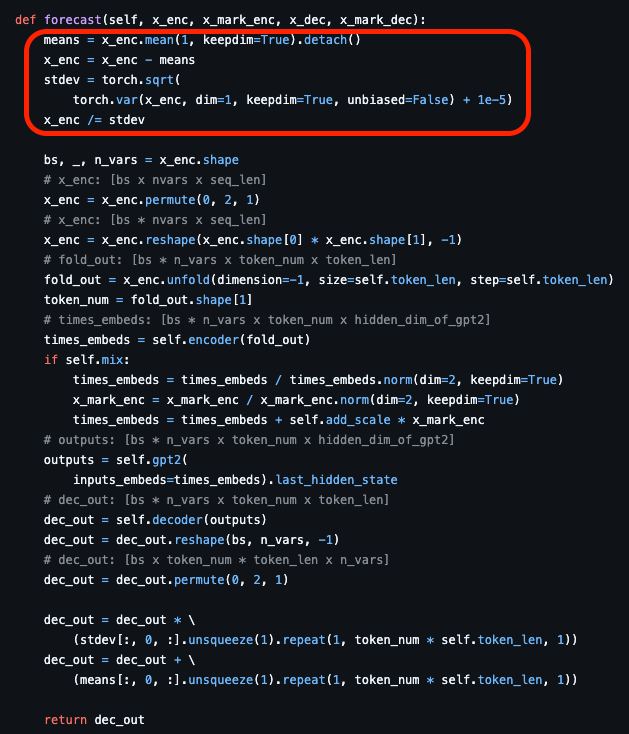
targets = self.revin(targets_norm, mode="denorm")그리고 정규화의 방식에 대해서도 저는 다른 방법을 채택했습니다.
학습할 때 데이터가 배치별로 섞이게 된다면
배치마다 평균, 분산으로 정규화를 하게 된다면
distribution shift에 크게 영향을 받을 것이라 생각해서
늘 revin을 이용한 정규화를 하는 편이라
AutoTimes의 공식 구현과는 다르게 RevIN을 이용한 정규화를 진행했습니다.
학습
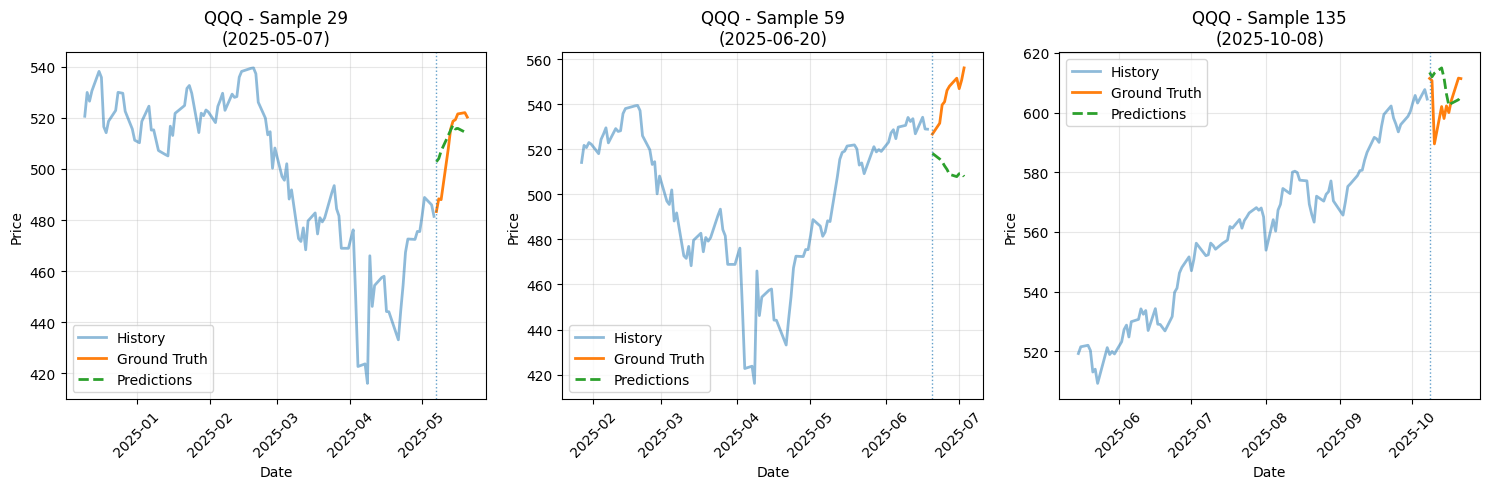
학습은 S&P500, 나스닥, 기간별 채권 추종 ETF 들의 가격을 예측하는 모델을 만들어보며 진행했습니다.
LLM 모델은 GPT2-small을 이용했습니다.
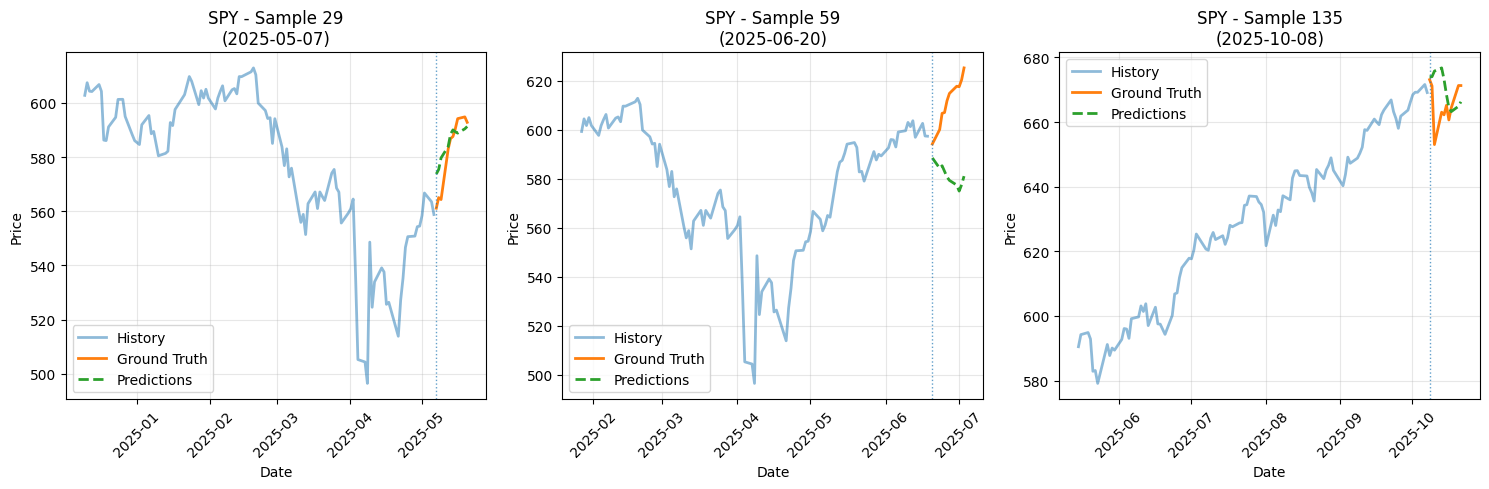
S&P500 추종 SPY
나스닥
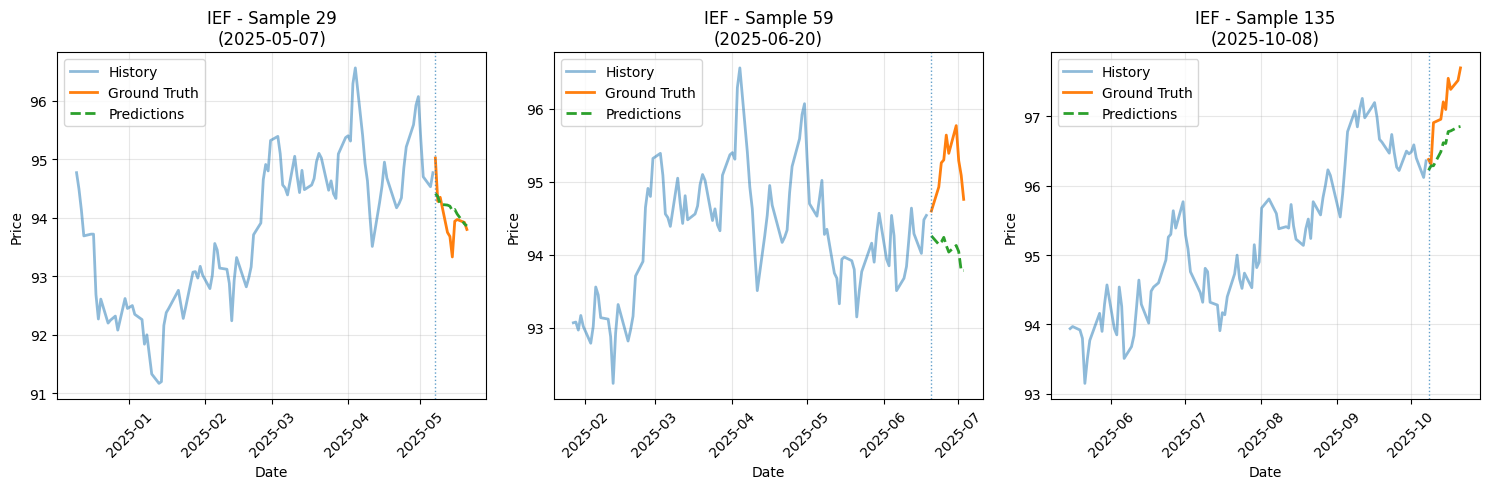
중기채
장기채
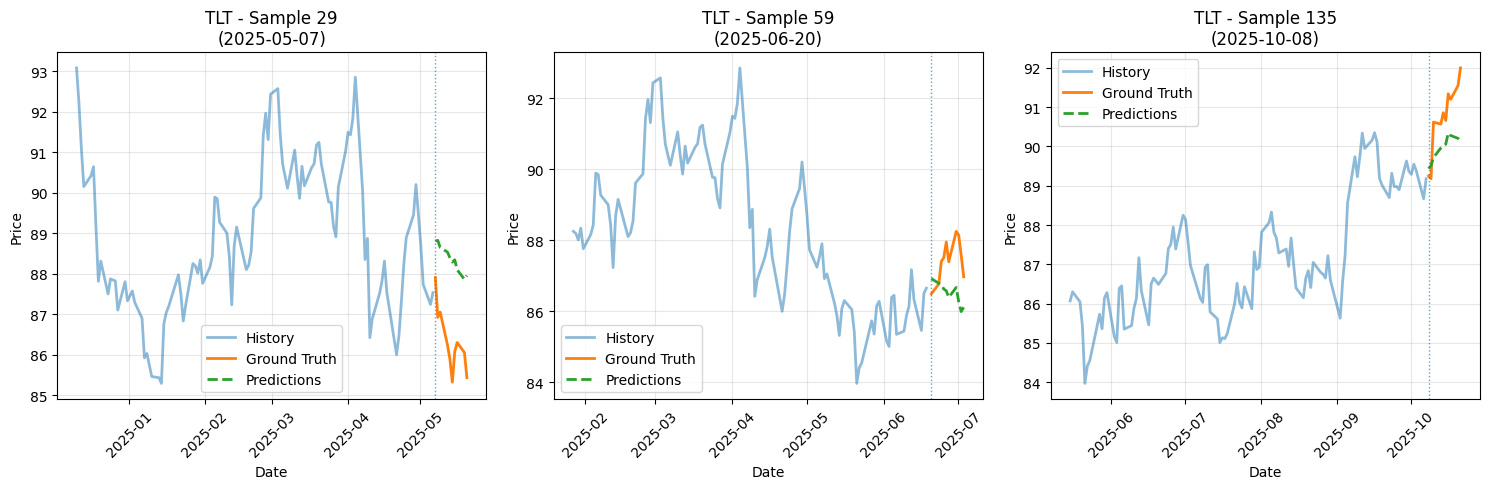
사실 예측기 파라미터가 크기 않은 선형적인 레이어로 이루어져있는데도
괜찮은 예측 성능을 내는 것 같습니다.
학습을 진행해보면서 장점으로 느껴진 것은
일단 기존 시계열 예측 모델들은
다양한 길이의 예측을 위해 여러 모델을 학습해야 했지만
이제는 하나의 모델로 장단기 예측을 함께 진행할 수 있다는 부분과
LLM 관련 연구와 활용이 많이 발전했기 때문에
이를 활용한 많은 시도들을 해볼 수 있는 장점이 있습니다.
기본적으로 언어모델을 탑재하고 있기 때문에 zero-shot 추론이나 가변적인 토큰 생성
추후 연구 방향
Segment Forecaster 개선
결국 시계열 데이터를 일정 세그먼트 토큰으로 치환하는 작업은 AutoTimes에도 필요합니다.
기존 시계열 예측 연구가 무의미하지 않은 이유가 결국 시계열에서
중요한 특성들을 추출하는 알고리즘이나 방법론들은 여전히 이 내부 예측기에 담아낼 수 있다는 것입니다.
기존에 연구된 훌륭한 알고리즘들을 AutoTimes 내부에 구현해서 더 뛰어난 성능을 갖출 수 있도록 하려고 합니다.
Diffusion Head
내부 예측기의 projection은 토큰의 생성, 즉 다음 시계열 데이터의 값들을 나열하고 있지만
diffusion, normalizing flow head를 추가하면
단일 예측값 대신 확률분포로 제공 가능합니다.
이는 주식시장에 어울리게 확률적인 시장 분석을 제공할 수 있다는 점에서
여러분들에게 더 유의미한 기능이 될 것 같습니다.
LLM Extension
저는 기존엔 계량투자에 기반하여 모델들을 만들어 왔습니다.
학습하고 취합할 수 있는 정량적인 수치데이터들을 기반으로 모델이 돌아가고 있지만
언어모델이 탑재 되어있기 때문에 더 많은 확장성이 확보되었습니다.
정량적인 데이터 외에 정성적인 컨텍스트를 LLM RAG에 담아두고
FOMC 등 주요 경제 이벤트들을 참고하거나
LangChain을 이용해서 추론 시점 많은 뉴스들을 참고하는 또 다른 LLM을 연동해 활용할 수 있습니다.
JeTech Lab
AI의 발전이 LLM을 기반으로 확장되어
다른 분야까지 영향을 끼치는 것을 보니, 제 서비스의 모델들도 LLM을 확장한 서비스를 고려하고 있습니다.
가변 길이의 예측이 가능해지거나
고려하는 투자 관점이나 스타일에 따른 예측 추천과 모델 추천
정성적인 데이터들을 살펴보고 여러분들의 투자 의사결정을 도울 수 있는
더 의미있는 요소들을 서비스에 녹여내려고 합니다.
잠시 JeTech Lab 서비스의 유료 플랜을 홍보하자면
Trading 영역이 플랜 이용자들에 한정된 기능으로 출시되었습니다.
많은 모델들의 실제 성과와 현재 확률적인 포지션 구축을 확인할 수 있고
여러 모델들의 조합을 통해서 시장 성과를 확인하거나 어떤 포지션을 취할 수 있는지 알 수 있습니다.
지금은 동종 업계에 비해 훨씬 저렴한 가격으로 제공되고 있습니다.
이게 가능한 이유는 투자성과가 저조한 것도 아니고
제가 많은 인력이 필요한 부분을 자동화 시켰기 때문입니다.
AI의 도움을 많이 받기도 했구요
그리고 플랜의 서비스는 지금이 최소지점입니다.
개발 업계에 새로운 기술이나 트렌드에 맞춰 항상 예의주시하고 있고
서비스에 접목할 수 있는 부분을 빨리 캐치해서
여러분들의 투자를 도울 수 있는 추가 기능을 제공할 예정입니다.
그러기 위해선 제가 더 많은 학습을 하고 연구할 수 있는 매출을 주시는
더 많은 유료 구독자분들이 필요합니다.
저는 이미 제 회사의 매출 대비 순수익률을 0에 수렴하게끔 많은 연구와 재투자로 돌리고 있습니다.
그게 궁극적으로 저에게 더 많은 수익률을 가져다 줄 수 있고
무엇보다 이 일 자체를 사랑하기 때문에 가능한 일입니다.
발전하는 모델과 서비스의 퀄리티에 따라
저는 물가인상률을 고려하여 서비스 가격을 주기적으로 인상할 예정입니다.
초기 서비스 유저분들은 가격 인하 프로모션이나 쿠폰제공 혹은 플랜 기간 확장과 같은 베네핏을 고려하고 있습니다.
많은 관심 부탁드립니다.
감사합니다.